Chapter 6
Public Transit Route Planning Over Lightweight Linked Data Interfaces
The impact of a feature on a Web api should be measured across implementations: measurable evidence about features should steer the api design decision process.
― Principle 5 of “A Web API ecosystem through feature-based reuse” by Ruben Verborgh and Michel Dumontier.
When publishing data for maximum reuse, http caching can make sure that through a standard adopted by various clients, servers, as well as intermediary and neighborhood caches [2], can be exploited to reach the user-perceived performance necessary, as well as the scalability/cost-efficiency of the publishing infrastructure itself. For that purpose, we can take inspiration from the locality of reference principle. Time schedules are particularly interesting from both the geospatial perspective as the time locality. Can we come up with a fragmentation strategy for time schedules?
When publishing departure-arrival pairs (connections) in chronologically ordered pages – as demonstrated in our 2015 demo paper [3] – route planning can be executed at data integration time by the user agent rather than by the data publishing infrastructure. This way, Linked Connections (lc) allows for a richer web publishing and querying ecosystem within public transit route planners. It lowers the cost for reusers to start prototyping – also federated and multimodal – route planners over multiple data sources. Furthermore, other sources may give more information about a certain specific vehicle that may be of interest to this user agent. It is not exceptional that route planners also take into account properties such as fares [4], wheelchair accessibility [5], or criminality statistics. In this chapter, we test our hypothesis that this way of publishing is more lightweight: how does our information system scale under more data reuse compared to origin-destination apis?
This rest of the chapter is structured in a traditional academic way, first introducing more details on the Linked Connections framework, to then describe the evaluation’s design, made entirely reproducible, and discuss our open-source implementation. Finally, we elaborate on the results and conclusion.
The Linked Connections framework
The time performance of csa, discussed in the previous chapter, is O(n) with n the number of input connections. These input connections are a subset of the set of connections in the real world. The smaller this subset, the lower the time consumption of the algorithm will be. Lowering the number of connections can be done using various methods involving preprocessing, end-user preferences, multi-overlay networks, geo-filtering, or other heuristics. The csa algorithm allows for an Open World Assumption while querying. The input connections that are fed in the algorithm are not all connections in existence, and when fed with other input connections, it may find a better journey. Furthermore, the stops and trips are discovered while querying: there is no need to keep a list of all trips and stops in existence. Thanks to the locality, extensibility and “open world” properties, three properties favorable for a Web environment, csa was chosen as the base algorithm for our framework.
IN: Ordered list of connections C, query q
arrivalTimes[q.departureStop] ← q.departureTime;
arrivalTimes[q.destinationStop] ← ∞;
c ← C.next();
while (c.departureTime <= arrivalTimes[q.destinationStop]) {
if (arrivalTimes[c.departureStop] < c.departureTime
AND arrivalTimes[c.arrivalStop] > c.arrivalTime) {
arrivalTimes[c.arrivalStop] ← c.arrivalTime;
minimumSpanningTree[c.arrivalStop] ← c;
}
c ← C.next();
}
return reconstructRoute(minimumSpanningTree, q);
To solve the eat problem using csa, timetable information within a certain time window needs to be retrievable. Other route planning questions need to select data within the same time window, and solving these is expected to have similar resultsAlso preprocessing algorithms [6] scan through an ordered list of connections to, for example, find transfer patterns [7]. Instead of exposing an origin-destination api or a data dump, a Linked Connections server paginates the list of connections in departure time intervals and publishes these pages over http. A public transit timetable, in the case of the base algorithm csa, is represented by a list of connections, ordered by departure time. Each page contains a link to the next and previous one. In order to find the first page a route planning needs, the document of the entry point given to the client contains a hypermedia description on how to discover a certain departure time. Both hypermedia controls are expressed using the Hydra vocabularyhttp://www.hydra-cg.com/spec/latest/core/.
The base entities that we need to describe are connections, which we documented using the lc Linked Data vocabulary (base uri: http://semweb.mmlab.be/linkedconnections#). Each connection entity – the smallest building block of time schedules – provides links to an arrival stop and a departure stop, and optionally to a trip. It contains two literals: a departure time and an arrival time. Linked gtfs can be used to extend a connection with public transit specific properties such as a headsign, drop off type, or fare information. Furthermore, it also contains concepts to describe transfers and their minimum change time. For instance, when transfering from one railway platform to another, Linked gtfs can indicate that the minimum change time from one stop to another is a certain number of seconds.

I implemented this hypermedia control as a redirect from the entry point to the page containing connections for the current time. Then, on every page, the description can be found of how to get to a page describing another time range. In order to limit the amount of possible documents, we only enable pages for each XX is a configurable amount minutes, and do not allow pages describing overlapping time intervals. When a time interval is requested for which a page does not exist, the user agent will be redirected to a page containing connections departing at the requested time. The same page also describes how to get to the next or previous page. This way, the client can be certain about which page to ask next, instead of constructing a new query for a new time interval.
{
"@context":{
"lc":"http://semweb.mmlab.be/ns/linkedconnections#",
"hydra":"http://www.w3.org/ns/hydra/core#",
"gtfs":"http://vocab.gtfs.org/terms#",
"cc" : "http://creativecommons.org/ns#"
},
"@id":"http://{host}/2017/apr/2",
"@type":"hydra:PagedCollection",
"cc:license":
"http://creativecommons.org/publicdomain/zero/1.0/",
"hydra:next":"http://{host}/2017/apr/3",
"hydra:previous":"http://{host}/2017/apr/1",
"hydra:search":{
"@type":"hydra:IriTemplate",
"hydra:template":"http://{host}/{?departureTime}",
"hydra:variableRepresentation":
"hydra:BasicRepresentation",
"hydra:mapping":{
"@type":"IriTemplateMapping",
"hydra:variable":"departureTime",
"hydra:required":true,
"hydra:property":"lc:departureTimeQuery"
}
},
"@graph":[
{
"@id":"http://{host}/a24fda19",
"@type":"lc:Connection",
"lc:departureStop":"http://{host}/stp/1",
"lc:departureTime":"2017-04-02T12:00:00Z",
"lc:arrivalStop":"http://{host}/stp/2",
"lc:arrivalTime":"2017-04-02T12:30:00Z",
"gtfs:trip":"http://{host}/trips/2017/1"
},
…
]
}
A naive implementation of federated route planning on top of this interface is also provided, as a client can be configured with more than one entry point. The client then performs the same procedure multiple times in parallel. The “connections streams” are merged and sorted as they are downloaded. A Linked Data solution is to ensure that the client knows how to link a stop from one agency to a stop from another.
Evaluation design
We implemented different components in JavaScript for the Node.js platform. We chose JavaScript as it allows us to use both components both on a command-line environment as well as in the browser.
- csa.js
- A library that calculates a minimum spanning tree and a journey, given a stream of input connections and a query
- Server.js
- Publishes streams of connections in JSON-LD, using a MongoDB to retrieve the connections itself
- Client.js
- Downloads connections from a configurable set of servers and executes queries
- gtfs2lc
- A tool to convert existing timetables as open data to the Linked Connections vocabulary
We set up 2 different servers, each connected to the same MongoDB database which stores all connections of the Belgian railway system for October 2015: The Belgian railway company estimates delays on its network each minute.
- A Linked Connections server with an nginx proxy cache in front, which adds caching headers configured to cache each resource for one minute and compresses the body of the response using gzip;
- A route planning server which exposes an origin-destination route planning interface using the csa.js library. The route planning server uses the csa.js library to expose a route planning api on top of data stored in a MongoDB. The code is available at https://github.com/linkedconnections/query-server.
In the lc without cache set-up, we introduce a set-up where the lc server is used as a data source by the end-user’s machine. A demo of an implementation in a browser can be viewed at http://linkedconnections.org, where the client.js was used as a library in the browser. The lc with cache set-up is where one user agent is doing all the querying on behalf of all end-users. Finally, with the traditional origin-destination approach, a data maintainer publishes a route planning service over http where one http request equals one route planning question, developed to be able to compare the previous two set-ups.
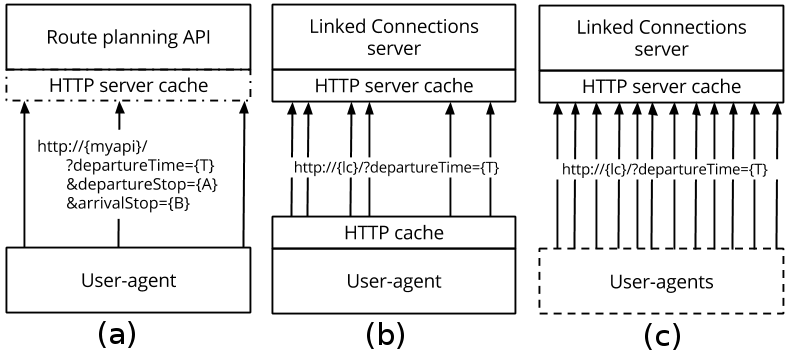
These tools are combined into different set-ups:
- Client-side route planning
- The first experiment executes the query mixes by using the Linked Connections client. Client caching is disabled, making this simulate the lc without cache set-up, where every request could originate from an end-user’s device.
- Client-side route planning with client-side cache
- The second experiment does the same as the first experiment, except that it uses a client side cache, and simulates the lc with cache set-up.
- Server-side route planning
- The third experiment launches the same queries against the full route planning server. The query server code is used which relies on the same csa.js library as the client used in the previous two experiments.
In order to have an upper and lower bound of a real world scenario, the first approach assumes every request comes from a unique user agent which cannot share a cache, and has caching disabled, while the second approach assumes one user agent does all requests for all end-users and has caching enabled. Different real world caching opportunities – such as user agents for multiple end-users in a software as a service model, or shared peer to peer neighborhood caching [2] – will result in a scalability in-between these two scenarios.
We also need a good set of queries to test our three set-ups with. The iRail project provides a route planning api to apps with over 100k installations on Android and iPhone [8]. The api receives up to 400k route planning queries per month. As the query logs of the iRail project are published as open data, we are able to create real query mixes from them with different loads. The first mix contains half the query load of iRail, during 15 minutes on a peak hour on the first of October. The mix is generated by taking the normal query load of iRail during the same 15 minutes, randomly ordering them, and taking the half of all lines. Our second mix is the normal query load of iRail, which we selected out of the query logs, and for each query, we calculated on which second after the benchmark script starts, the query should be executed. The third mix is double the load of the second mix, by taking the next 15 minutes, and subtracting 15 minutes from the requested departure time, and merging it with the second mix. The same approach can be applied with limited changes for the subsequent query mixes, which are taken from the next days’ rush hours. Our last query mix is 16 times the query load of iRail on the 1st of October 2015. The resulting query mixes can be found at https://github.com/linkedconnections/benchmark-belgianrail.
These query mixes are then used to reenact a real-world query load for three different experiments on the three different architectures. We ran the experiments on a quad core Intel(R) Core(TM) i5-3340M cpu @ 2.70GHz with 8GB of RAM. We launched the components in a single thread as our goal is to see how fast cpu usage increases when trying to answer more queries. The results will thus not reflect the full capacity of this machine, as in production, one would run the applications on different worker threads.
Our experiments can be reproduced using the code at https://github.com/linkedconnections/benchmark-belgianrail. There are three metrics we gather with these scripts: the cpu time used of the server instance (http caches excluded), the bandwidth used per connection, and the query execution time per lc connection. For the latter two, we use a per-connection result to remove the influence of route complexity, as the time complexity of our algorithm is O(n) with n the total number of connections. We thus study the average bandwidth and query execution time needed to process one connection per route planning task.
Results of the overall cost-efficiency test
Figure 3 depicts the percentage of the time over 15 minutes the server thread was active on a cpu. The server cpu time was measured with the command pidstat from the sysstat package and it indicates the server load. The faster this load increases, the quicker extra cpus would be needed to answer more queries.

When the query load is half of the real iRail load on October 1st 2015, we can see the lowest server load is the lc set-up with client cache. About double of the load is needed by the lc without client cache set-up, and even more is needed by the query server. When doubling the query load, we can notice the load lowers slightly for lc with cache, and the other two raise slightly. Continuing this until 16 times the iRail query load, we can see that the load of the query server raises until almost 100%, while lc without cache raises until 30%, while with client cache, 12% is the measured server load.
| query load | lc no cache | lc with cache | Query server |
| 0.5 | 4.61% | 2.44% | 4.95% |
| 1 | 4.97% | 2.32% | 5.62% |
| 2 | 7.21% | 3.50% | 10.41% |
| 4 | 11.23% | 5.39% | 21.37% |
| 8 | 17.69% | 7.98% | 35.77% |
| 12 | 20.34% | 9.38% | 70.24% |
| 16 | 28.63% | 11.71% | 97.01% |
In Figure 4, we can see the query response time per connection of 90% of the queries. When the query load is half of the real iRail load on October 1st 2015, we notice that the fastest solution is the query server, followed by the lc with cache. When doubling the query load, the average query execution time is lower in all cases, resulting in the same ranking. When doubling the query load once more, we see that lc with client cache is now the fastest solution. When doubling the query load 12 times, also the lc without client cache becomes faster. The trend continues until the the query server takes remarkably longer to answer 90% of the queries than the Linked Connections solutions at 16 times the query load.

The average bandwidth consumption per connection in bytes shows the price of the decreased server load as the bandwidth consumption of the lc solutions are three orders of magnitude bigger: lc is 270B, lc with cache is 64B and query-server is 0.8B. The query server only gives one response per route planning question which is small. lc without client cache has a bandwidth that is three orders of magnitude bigger than the query server. The lc with a client cache has an average bandwidth consumption per connection that is remarkably lower. On the basis of these numbers we may conclude the average cache hit-rate is about 78%.
| query load | lc no cache | lc with cache | Query server |
| 0.5 | 0.319 | 0.211 | 0.130 |
| 1 | 0.269 | 0.165 | 0.125 |
| 2 | 0.266 | 0.177 | 0.151 |
| 4 | 0.273 | 0.177 | 0.188 |
| 8 | 0.302 | 0.211 | 0.255 |
| 12 | 0.389 | 0.307 | 0.539 |
| 16 | 0.649 | 0.369 | 3.703 |
Linked Connections with wheelchair accessibility
In order to study how to add extra features to this framework, we performed another experiment, in order to test the impact of this extra feature on both the client and server. A wheelchair accessible journey has two important requirements: first, all vehicles used for the route should be wheelchair accessible. Thus, the trip (a sequence of stops that are served by the same vehicle), should have a wheelchair accessible flag set to true when there is room to host a wheelchair on board. Secondly, every transfer stop, the stop where a person needs to change from one vehicle to another vehicle, should be adapted for people with limited mobility. As the lc server does not know where the traveler is going to hop on as it only publishes the time tables in pages, it will not be able to filter on wheelchair accessible stops.
When extending the framework of Linked Connections with a wheelchair accessibility feature, there are two possible ways of implementing this:
- Filter both the wheelchair accessible trips and stops on the client;
- Only filter the wheelchair accessible trips on the server while filtering the stops on the client.
Linked Connections with filtering on the client
In a first approach, the server does not expose wheelchair accessibility information and only exposes the Linked Data of the train schedules using the Linked Connections vocabulary. The client still calculates wheelchair accessible journeys on the basis of its own sources. We thus do not extend the server: the same server interface is used as in lc without wheelchair accessibility. The lc client however is extended with two filter steps: the first filter removes all connections from the connections stream whose trip is not wheelchair accessible. The second filter is added to csa, to filter the transfers stops. When csa adds a new connection to the minimum spanning tree, it detects whether this would lead to a transfer. csa can use the information from stops in the Linked Open Data cloud to decide if the transfer can be made and the connection can be added to the minimum spanning tree. To be able to support dynamic transfers times, csa can also request Linked Data on “transfers” from another source. When a transfer is detected, csa will add the transfer time to the departure time of the connection. The trips, stops, and transfers in our implementation are simple json-ld documents. They are connected to a module called the data fetcher that takes care of the caching and pre-fetching of the data.
This solution provides an example of how the client can now calculate routes using more data than the data published by the transit companies. As wheelchair accessibility is specified in the gtfs standard, we can expect that the public transit companies provide this data. In practice we have noticed that the data is mostly not available, which can be considered normal for an optional field. This makes us believe an external organisation that represents the interests of the less mobile people should be able to publish this data.
Linked Connections with filtering on the server and client
In the Linked Connections solution with filtering on both server and client-side, the server still publishes the time schedules as Linked Data, yet an extra hypermedia control is added to the lc server to enable the trips filter on the resulting connections. The wheelchair accessibility information is directly added to the servers’ database, and an index is configured, so that the lc server can query for this when asked.
Wheelchair accessibility feature experiment
Evaluation design
The purpose of the evaluation is to compare the two lc solutions based on the scalability of the server-interface, the query execution time of an eat query, and the cpu time used by the client. For this evaluation, we used the same query mixes as in the previous experiment.
Two lc servers, one for the lc with filtering on the client setup and one for the lc with trips filtering on the server setup. The MongoDBs used by the lc servers are populated with connections of the Belgian railway company of 2015. Also a transfers, trips and stops resource as a data source for the wheelchair accessibility information is created.
Results
Figure 5 contains the cpu load of the server. The server interface with filtering on the server has a similar scalability as without the filter functionality. However, an average raise of 1.24% in processing power needed, can be noticed.

In Figure 6, we can see the cpu load of the client performing the algorithm. When the query load is half of the real iRail load, we notice that the load is 20% for filtering on the client and 21% for trips filtering on the server. Continuously increasing the query load results in an increased client cpu load. The client load of the solution with filtering on the client increases from 27% at query mix 1 to 93% at query-mix 16 while the solution with filtering on the server-side increases from respectively 30% to 93%. For query loads higher than 12 times the iRail load the difference between the two solution becomes less than 1%.

Figure 7 shows the average query response time per connection. We notice that the fastest solution is the solution with filtering on the client for lower query loads, yet for higher query loads, the execution times become comparable.

When observing half of the normal iRail query load the measured cache rate is 76% and 70% for respectively with filtering on the client as with trip filtering on the server. The cache hit rate slowly decreases to respectively 70% and 64% at query mix 8 and finally to 64% and 61% at the highest query mix 16. When observing all query loads, the cache hit rate measured from the Linked Connections framework with filtering on the client is lower than the framework with filtering on both client and server-side.
When comparing the two lc implementations we can observe that moving the trips filter from the client to the server-side does not cause an improvement of the query execution time. The cache performance is better for the client-side filtering solution because the hybrid solution needs an extra parameter to query the lc server. This results in more unique requests and consequently in a lower cache hit rate. The loss of cache performance increases the number of requests that the lc server needs to handle, which leads to a higher cpu load at the server-side and an increased query execution time. The difference becomes smaller as the query load increases, as more queries can use the already cached Linked Connections documents.
Discussion
The results look promising: thanks to a cache hit-rate of 78%, the Linked Connections server is able to handle more queries than the traditional query server approach.
Network latency
In the evaluation, we tested two extremes: one where the user agent can cache nothing, being an end-user application, and another, where the user agent can cache all end-user questions. The latter can be an intermediate traditional api with a back-end that uses something similar to the Linked Connections client. The cost-efficient interfaces of Linked Connections can this way also be used as a new way to exchange public transit data, while the end-users still get small responses.
Actual query response times
The average number of connections in the journeys of the results, multiplied with the query execution time per connection will give an idea of the average waiting time per route planning query. For the Belgian railway system, based on the iRail query logs, we scan an average of 2700 connections per query. For the entire Belgian railway system as input connections, route planning queries will on average, even in the case of 16 times the iRail query load, return results under 2 seconds, again network latency not taken into account.
More advanced federated route planning
The current approach is simple: when multiple entrypoints are configured, data will be downloaded by following links in both entrypoints. The stream of connections that comes in will be ordered just in time, and provided to the csa algorithm. Further research and engineering is needed to see how sources would be able to be selected just in time. E.g., when planning a route from one city to another, a planning algorithm may first prioritize a bus route to border stations in the first city, to then only query the overarching railway network, to then only query the bus company in the destination city.
Denser public transport networks
The number of connections in a densily populated area like Paris or London are indeed much higher than in other areas. In order to scale this up to denser areas, the key would be to split the dataset in smaller regions. This would allow for federated querying techniques to prune the to be queried parts of the Linked Connections datasets. This fragmentation strategy could also allow for parallel processing, limiting the time the client is waiting for data to be downloaded.
A generic approach for fragmentation strategies for data in ordered ranges has been put in the multidimensional interfaces ontology [9], which takes inspiration from B-trees and R-trees. We leave it as a challenge to future research to apply concepts like multi-overlay networks [1] to Linked Connections.
Real-time updates: accounting for delays
As the lc pages in the proof of concept are generated from a Mongodb store, updating a departure time or arrival time will result in the new data being queryable online. However, user agents querying pages may experience problems when connections suddenly shift pages. One possible solution to this is to use Memento on top of the http server, making the lc client able to query a fixed version. Another solution would be to keep the updated connection in all pages. When the algorithm detects a duplicate connection, it can take the last version of the object or choose to restart the query execution.
Beyond the eat query
The basic csa algorithm solving the eat problem can be extended to various other route planning questions for which we refer to the paper in which csa was introduced [1]. Other queries may for instance include Minimum Expected Arrival Times, a set of Pareto optimal routes [1], isochrone studies, or analytical queries studying connections with a certain property. For all of these queries, it is never necessary to download the entire dataset: only the window of time that is interesting to the query can be used.
On disk space consumption
gtfs contains rules, while the Linked Connections model contains the result of these rules. In the current implementation, the result of a 2MB gtfs can easily be 2GB of Linked Connections. However, on the one hand, we can come up with systems that generate Linked Connections pages from a different kind of rules dynamically. On the other hand, keeping an identifier on disk for each connection that ever happened and is planned to happen, is an interesting idea for analytical purposes. E.g., in Belgium, iRail is now using the Linked Connections model to keep a history of train delays and an occupancy score [8] and execute analytical queries over it.
Non-measurable benefits
While bandwidth, cpu load, and query execution times are measurable, there are also other design aspects to take into account, which are not directly measurable. For instance, in the case where end-user machines execute the route planning algorithm, privacy is engineered by design: a man in the middle would not be able to determine from where to where the end-user is going. As the client is now in control of the algorithm, we can now give personalized weights to connections based on subscriptions the end-user has or we can calculate different transfer times based on how fast you can walk, without this information having to be shared with the public transit agencies.
Conclusion
We measured and compared the raise in query execution time and cpu usage between the traditional approach and Linked Connections. We achieved a better cost-efficiency: when the query-interface becomes saturated under an increasing query load, the lightweight lc interface only reached 1/4th of its capacity, meaning that the same load can be served with a smaller machine, or that a larger amount of queries can be solved using the same server. As the server load increases, the lc solution even – counter-intuitively – gives faster query results.
These result are strong arguments in favor of publishing timetable data in cacheable fragments instead of exposing origin-destination query interfaces when publishing data for maximum reuse is envisioned. The price of this decreased server load is however paid by the bandwidth that is needed, which is three orders of magnitude bigger. When route planning advice needs to be calculated while on, for example, a mobile phone network, network latency, which was not taken into account during the tests, may become a problem when the cache of the device is empty. An application’s server can however be configured with a private origin-destination api, which in its turn is a consumer of a Linked Connections dataset, taking the best of both worlds. When exposing a more expressive server interface, caution is advised. For instance in the case of a wheelchair accessibility feature, the information system would become less efficient when exposing this on the server interface.
Our goal was to enable a more flexible public transport route planning ecosystem. While even personalized routing is now possible, we also lowered the cost of hosting the data, and enabled in-browser scripts to execute the public transit routing algorithm. Furthermore, the query execution times of queries solved by the Linked Connections framework are competitive. Until now, public transit route planning was a specialized domain where all processing happened in memory on one machine. We hope that this is a start for a new ecosystem of public transit route planners.
References
- [1]
- Strasser, B., Wagner, D. (2014). Connection Scan Accelerated. Proceedings of the Meeting on Algorithm Engineering & Expermiments (pp. 125–137).
- [2]
- Folz, P., Skaf-Molli, H., Molli, P. (2016). CyCLaDEs: A Decentralized Cache for Triple Pattern Fragments. The Semantic Web. Latest Advances and New Domains: 13th International Conference (pp. 455–469). Springer International Publishing.
- [3]
- Colpaert, P., Llaves, A., Verborgh, R., Corcho, O., Mannens, E., Van de Walle, R. (2015). Intermodal Public Transit Routing using Linked Connections. In proceedings of International Semantic Web Conference (Posters & Demos).
- [4]
- Delling, D., Pajor, T., Werneck, R. (2012). Round-Based Public Transit Routing. Proceedings of the 14th Meeting on Algorithm Engineering and Experiments (ALENEX’12).
- [5]
- Colpaert, P., Ballieu, S., Verborgh, R., Mannens, E. (2016). The impact of an extra feature on the scalability of Linked Connections. In proceedings of iswc2016.
- [6]
- Witt, S. (2016). Trip-Based Public Transit Routing Using Condensed Search Trees. Computing Research Repository (corr).
- [7]
- Bast, H., Carlsson, E., Eigenwillig, A., Geisberger, R., Harrelson, C., Raychev, V., Viger, F. (2010). Fast routing in very large public transportation networks using transfer patterns. Algorithms – esa 2010 (pp. 290–301). Springer.
- [8]
- Colpaert, P., Chua, A., Verborgh, R., Mannens, E., Van de Walle, R., Vande Moere, A. (2016, April). What public transit api logs tell us about travel flows. In proceedings of the 25th International Conference Companion on World Wide Web (pp. 873–878).
- [9]
- Taelman, R., Colpaert, P., Verborgh, R., Mannens, E. (2016, August). Multidimensional Interfaces for Selecting Data within Ordinal Ranges. Proceedings of the 7th International Workshop on Consuming Linked Data.